
Photo by Anatoliy Shostak on Unsplash
I rarely take the time to step back after releasing a new feature on Juno. I generally build, build, build, ship, and repeat. On top of that, writing long blog posts often feels like a relative waste of time, as they rarely find their audience. Nonetheless, for once, I thought I'd take a moment to write about what I released recently: deploying frontends or publishing serverless functions from GitHub Actions using ephemeral access keys granted through an OpenID Connect flow.
The following is a walkthrough of the solution. I'll go through the various steps required to implement such a workflow and highlight the pieces I feel are important.
It won't be a tutorial, nor something you or your AI can — or should — copy-paste to implement a similar outcome. But hopefully it contains something interesting — or at least leads someone to reach out for suggestions of improvements.
Introduction
Authenticating CI/CD pipelines without long-lived secrets is not a new concept and, even though I kind of randomly learned about it, GitHub Actions has been supporting OpenID Connect for a while now.
The idea is simple: instead of storing a secret that can leak, rotate, or be forgotten, the CI generates a short-lived token — a JWT that proves where the workflow is running: which repository, which branch, which actor.
The twist is that the other end is not a typical server. In Juno, the developer's application is in a Rust WASM container (which I call a Satellite) running on the Internet Computer. Since the underlying infrastructure is a public blockchain, sensitive information has to be handled carefully — secrets cannot simply be stored and trusted the way they would on a traditional server.
That's what makes the implementation a bit particular, and why the flow ultimately goes through quite a few steps and assertions.
To give you an idea, the diagram below summarizes the flow, from the moment a GitHub Actions workflow is triggered to the moment the ephemeral access key is approved for use.
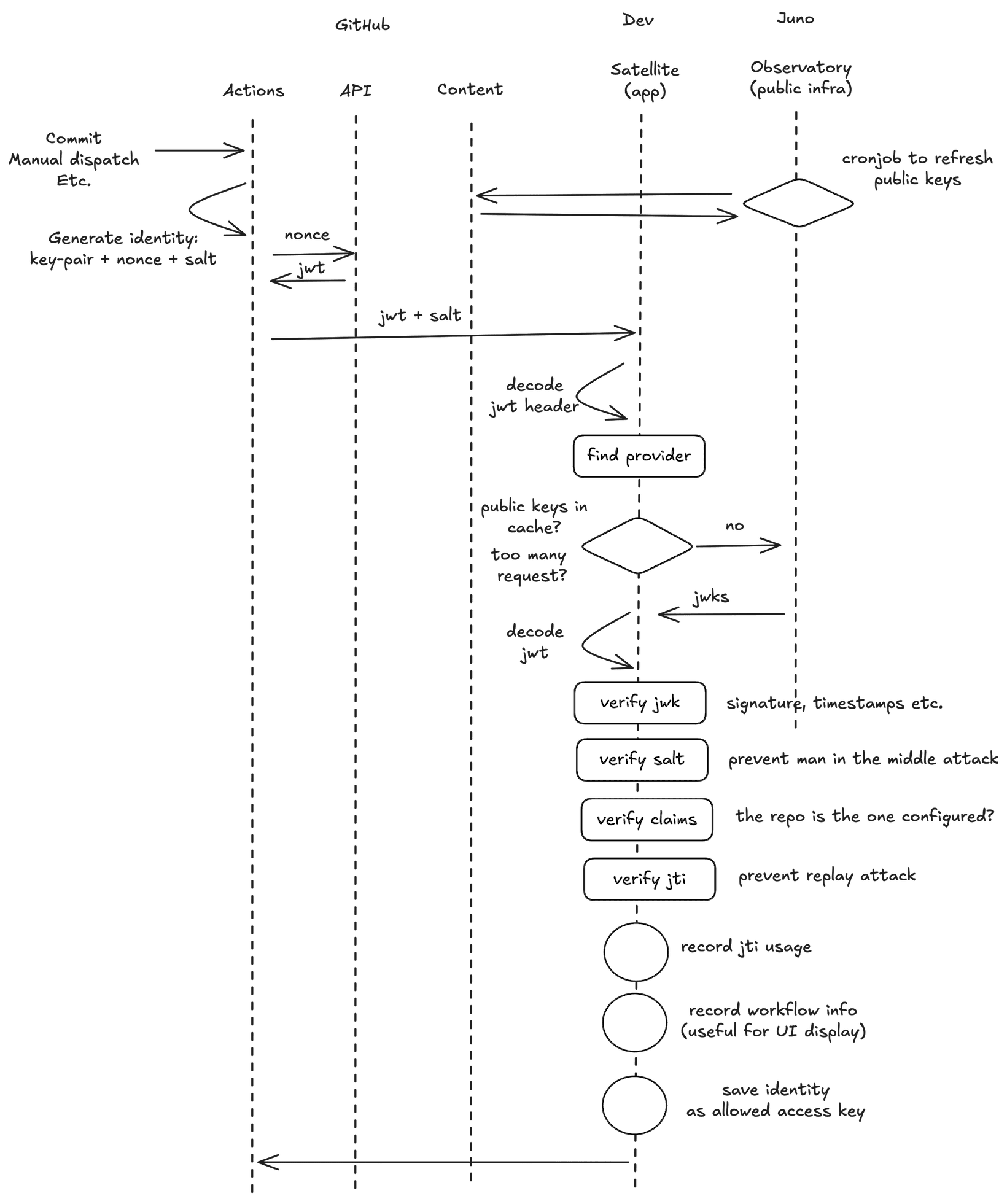
Before any deployment happens, the Actions workflow generates an identity — a key-pair, a nonce, and their corresponding salt. It then exchanges the nonce with GitHub's API to obtain a signed JWT that also contains information about the repository, actor, and workflow.
This JWT, along with the salt, is sent to the satellite using the generated identity. An identity is essentially a private-public key pair.
On the satellite side, the JWT header is decoded first to identify the provider ("is it GitHub calling?"), then the public keys are retrieved — either from cache or from Observatory, Juno's public infrastructure, which runs a cronjob to keep those keys fresh.
From there, the satellite runs a series of verifications: the JWK signature and timestamps, the salt to prevent man-in-the-middle attacks, the claims to confirm the request comes from the configured repository, and finally the JTI to prevent replay attacks.
If everything passes, the identity is saved as an allowed access key and the workflow can proceed with the deployment.
From there it's standard Juno usage — the GitHub Action uploads a file, and the access key is validated to approve or reject the operation. I won't cover that part here, there are already enough steps as it is 😅.
Alright, ready? There are quite a few moving parts here, so buckle up, the following chapters will go through each piece in detail.
The GitHub Action
The entry point of the integration is a bash script (source). Nothing fancy, it checks which command is being run, decides whether authentication is needed, and if so, generates an ephemeral token before passing it to the CLI.
JUNO_TOKEN=$(node /kit/token/src/authenticate.ts "$@")
echo "::add-mask::$JUNO_TOKEN"
export JUNO_TOKENTwo things worth noting here:
- The generated token is passed as
JUNO_TOKEN, the same environment variable the CLI already supports. No changes were needed in the CLI itself, which was a nice side effect of the approach. ::add-mask::ensures the token never appears in the Actions logs, even accidentally. We do not want to leak the private key in some logs...
From there, a custom script within the action takes over. I like abstraction, so rather than implementing the authentication flow directly, it delegates to @junobuild/auth — a library I maintain — through a single function call: authenticateAutomation (source).
const { identity } = await authenticateAutomation({
github: {
credentials: {
generateJwt
},
automation: {
satellite: {
container,
satelliteId
}
}
}
});The library doesn't know anything about GitHub. It just knows it needs a JWT and will ask for one by calling the generateJwt callback. This means the action is responsible for implementing that callback: taking the nonce, calling GitHub's token endpoint, and returning the signed JWT.
const generateJwt = async ({ nonce }: { nonce: string }) => {
const response = await fetch(`${process.env.ACTIONS_ID_TOKEN_REQUEST_URL}&audience=${nonce}`, {
headers: {
Authorization: `Bearer ${process.env.ACTIONS_ID_TOKEN_REQUEST_TOKEN}`,
Accept: "application/json; api-version=2.0",
"Content-Type": "application/json"
}
});
if (!response.ok) {
throw new Error("Could not retrieve token");
}
const { value: oidcToken } = await response.json();
return { jwt: oidcToken };
};You may notice audience=${nonce} in the URL. This is a workaround: GitHub does not allow customizing any fields of the JWT aside from the aud (audience) claim. So I use that field, which is not really meant for this purpose, to pass the nonce along.
process.env.ACTIONS_ID_TOKEN_REQUEST_URL and process.env.ACTIONS_ID_TOKEN_REQUEST_TOKEN are environment variables that GitHub automatically injects into the workflow, but only if the workflow declares id-token: write permissions.
That nonce passed to the callback is generated by the library itself before calling back, and it is not purely random. It is derived from a SHA-256 hash of a salt and the identity's principal (basically a public key), encoded as a base64 URL string (source).
const generateSalt = (): Salt => crypto.getRandomValues(new Uint8Array(32));
const buildNonce = async ({ salt, caller }: { salt: Salt; caller: Ed25519KeyIdentity }) => {
const principal = caller.getPrincipal().toUint8Array();
const bytes = new Uint8Array(salt.length + principal.byteLength);
bytes.set(salt);
bytes.set(principal, salt.length);
const hash = await crypto.subtle.digest("SHA-256", bytes);
return toBase64URL(arrayBufferToUint8Array(hash));
};This matters because the satellite will later reconstruct the nonce from the same inputs and verify it matches, which is what prevents man-in-the-middle attacks.
Note that
calleris our identity, our access key. I use the three terms interchangeably in this post.
Once the JWT is obtained, it is sent to the satellite along with the salt, using the generated identity as the caller (source).
const result = await authenticateAutomationApi({
args: {
OpenId: {
jwt,
salt
}
},
actorParams: {
automation,
identity: caller
}
});If the satellite approves, the identity is returned as the ephemeral access key, serialized and passed back to the CLI as JUNO_TOKEN.
Later on, a cleanup step, registered as a trap on exit of the entry script, takes care of removing the access key from the satellite once the workflow is done (regardless of whether it succeeded or failed).
The Satellite
On the Rust side, the entry point is openid_prepare_automation (source). It receives the JWT and the salt sent by the action, and kicks off the verification chain.
pub async fn openid_prepare_automation(
args: &OpenIdPrepareAutomationArgs,
providers: &OpenIdAutomationProviders,
) -> OpenIdPrepareAutomationResult {
let (credential, provider) =
match credentials::automation::verify_openid_credentials_with_jwks_renewal(
&args.jwt, &args.salt, providers, &AuthHeap,
)
.await
{
Ok(value) => value,
Err(err) => return Err(PrepareAutomationError::from(err)),
};
let result = automation::openid_prepare_automation(&provider, &AuthHeap, &AuthAutomation);
result.map(|prepared_automation| (prepared_automation, provider, credential))
}The first thing verify_openid_credentials_with_jwks_renewal (source) does is figure out who is calling. It decodes the JWT header without verifying the signature, just enough to read the issuer (iss) which identifies who generated the token ("is this GitHub? Google? Something else?") and matches it against the configured providers.
This is safe because the signature verification happens right after — skipping it here is just a pragmatic shortcut to avoid fetching the wrong set of public keys. (source)
pub fn unsafe_find_jwt_provider<'a, Provider, Config>(
providers: &'a BTreeMap<Provider, Config>,
jwt: &str,
) -> Result<(Provider, &'a Config), JwtFindProviderError>
where
Provider: Clone + JwtIssuers,
{
decode_jwt_header(jwt).map_err(JwtFindProviderError::from)?;
let token_data = dangerous::insecure_decode::<UnsafeClaims>(jwt)
.map_err(|e| JwtFindProviderError::BadSig(e.to_string()))?;
if let Some(iss) = token_data.claims.iss.as_deref() {
if let Some((prov, cfg)) = providers
.iter()
.find(|(provider, _)| provider.issuers().contains(&iss))
{
return Ok((prov.clone(), cfg));
}
}
Err(JwtFindProviderError::NoMatchingProvider)
}Once the provider is identified, the public keys are retrieved. The satellite first checks its cache. If the keys are not there, or the specific kid (key ID) referenced in the JWT header is not found, it fetches fresh keys from Observatory (described in the next chapter), Juno's public infrastructure. There is also a rate limiting mechanism to avoid hammering the key endpoint if something goes wrong. (source)
pub async fn get_or_refresh_jwks(
provider: &OpenIdProvider,
jwt: &str,
observatory_id: Principal,
auth_heap: &impl AuthHeapStrategy,
) -> Result<Jwks, GetOrRefreshJwksError> {
let unsafe_kid = unsafe_find_jwt_kid(jwt)?;
// Check cache first
let cached_jwks = ...;
if let Some(cached_jwks) = cached_jwks {
return Ok(cached_jwks);
}
// Rate limiting check before fetching
match refresh_allowed(&cached_certificate) {
RefreshStatus::Denied => return Err(GetOrRefreshJwksError::KeyNotFoundCooldown),
_ => { /* proceed */ }
}
// Fetch from Observatory
let fetched_certificate = fetch_openid_certificate(provider, observatory_id).await?;
cache_certificate(provider, &fetched_certificate, auth_heap)?;
Ok(fetched_certificate.jwks)
}With the public keys in hand, the actual JWT verification happens in verify_openid_jwt (source). This is where the signature is checked, the issuer validated, the nonce reconstructed and compared, and the timestamps asserted.
A few things worth highlighting before diving into the code.
expvalidation is disabled intentionally. Instead of relying on the token's own expiration field, the satellite enforces a strict 10-minute window based oniat(issued at). This avoids trusting a field that the token issuer controls and that could in theory be set to a far future date.- The nonce is reconstructed on the satellite side from the salt, and compared against the
audclaim in the JWT. If they do not match, the request is rejected. This is the man-in-the-middle protection — even if someone intercepted the JWT, they could not reuse it with a different identity.
build_nonceis the Rust mirror of the JavaScriptbuildNoncefunction shown earlier — same algorithm, same inputs (salt + caller principal), different language. The symmetry is what makes the verification work end to end.
pub fn build_nonce(salt: &Salt) -> String {
let mut hasher = Sha256::new();
hasher.update(salt);
hasher.update(caller().as_slice());
let hash: [u8; 32] = hasher.finalize().into();
URL_SAFE_NO_PAD.encode(hash)
}With that in mind, here is the full verification function:
pub fn verify_openid_jwt<Claims, Custom>(
jwt: &str,
issuers: &[&str],
jwks: &[Jwk],
salt: &Salt,
assert_custom: Custom,
) -> Result<TokenData<Claims>, JwtVerifyError>
where
Claims: DeserializeOwned + JwtClaims,
Custom: FnOnce(&Claims) -> Result<(), JwtVerifyError>,
{
let header = decode_jwt_header(jwt).map_err(JwtVerifyError::from)?;
let kid = header.kid.ok_or(JwtVerifyError::MissingKid)?;
let jwk = pick_key(&kid, jwks).ok_or(JwtVerifyError::NoKeyForKid)?;
let (n, e) = match (&jwk.kty, &jwk.params) {
(JwkType::Rsa, JwkParams::Rsa(params)) => (¶ms.n, ¶ms.e),
_ => return Err(JwtVerifyError::WrongKeyType),
};
let key = DecodingKey::from_rsa_components(n, e)
.map_err(|e| JwtVerifyError::BadSig(e.to_string()))?;
let mut val = Validation::new(Algorithm::RS256);
val.validate_exp = false;
val.validate_nbf = true;
val.set_issuer(issuers);
val.validate_aud = false;
let token =
decode::<Claims>(jwt, &key, &val).map_err(|e| JwtVerifyError::BadSig(e.to_string()))?;
let c = &token.claims;
let nonce = build_nonce(salt);
if c.nonce() != Some(nonce.as_str()) {
return Err(JwtVerifyError::BadClaim("nonce".to_string()));
}
assert_custom(c)?;
let now_ns = now_ns();
const MAX_VALIDITY_WINDOW_NS: u64 = 10 * 60 * 1_000_000_000;
const IAT_FUTURE_SKEW_NS: u64 = 2 * 60 * 1_000_000_000;
let iat_ns = c.iat().ok_or(JwtVerifyError::BadClaim("iat".to_string()))?
.saturating_mul(1_000_000_000);
if now_ns < iat_ns.saturating_sub(IAT_FUTURE_SKEW_NS) {
return Err(JwtVerifyError::BadClaim("iat_future".to_string()));
}
if now_ns > iat_ns.saturating_add(MAX_VALIDITY_WINDOW_NS) {
return Err(JwtVerifyError::BadClaim("iat_expired".to_string()));
}
Ok(token)
}The custom claim assertion is passed as a callback — assert_custom — keeping the core verification logic generic and reusable as I reuse the same validation for other flows such as user browser-based authentications.
For the GitHub Actions flow, this callback checks that the repository claim matches one of the configured repositories, and optionally that the ref (branch or PR) is in the allowed list. In other words, it checks the provided information against what the developer has configured.
let assert_repository = |claims: &AutomationClaims| -> Result<(), JwtVerifyError> {
let repo_key = RepositoryKey { owner, name };
let repo_config = config.repositories.get(&repo_key)
.ok_or_else(|| JwtVerifyError::BadClaim("repository_unauthorized".to_string()))?;
if let Some(allowed_refs) = &repo_config.refs {
if !allowed_refs.contains(ref_claim) {
return Err(JwtVerifyError::BadClaim("ref_unauthorized".to_string()));
}
}
Ok(())
};If all verifications pass, the identity is saved as an allowed access key on the satellite, and the workflow can proceed.
In practice, the full authentication flow looks like this (source):
pub async fn openid_authenticate_automation(
args: &OpenIdPrepareAutomationArgs,
) -> Result<AuthenticateAutomationResult, String> {
let providers = get_automation_providers(&AuthHeap)?;
let prepared_automation = prepare::openid_prepare_automation(args, &providers).await;
let result = match prepared_automation {
Ok((automation, provider, credential)) => {
if let Err(err) = save_unique_token_jti(&automation, &provider, &credential) {
return Ok(Err(AuthenticationAutomationError::SaveUniqueJtiToken(err)));
}
if let Err(err) = save_workflow_metadata(&provider, &credential) {
return Ok(Err(AuthenticationAutomationError::SaveWorkflowMetadata(err)));
}
if let Err(err) = register_controller(&automation, &provider, &credential) {
return Ok(Err(AuthenticationAutomationError::RegisterController(err)));
}
Ok(automation)
}
Err(err) => Err(AuthenticationAutomationError::PrepareAutomation(err)),
};
Ok(result)
}One last thing worth mentioning: JTI replay protection. The verification function intentionally does not handle replay attacks on its own — that responsibility is left to the consumer of the crate (here again, I love abstraction therefore I use multiple layers). That's why save_unique_token_jti records the JTI only if it hasn't been seen before, rejecting any future request using the same token.
Then the workflow metadata is saved — this is what powers the deployment history displayed in the Juno console — and finally the identity is registered as a controller, the ephemeral access key that the CLI will use for the rest of the workflow.
The Observatory
The Observatory is Juno's public infrastructure. Among other things, it is responsible for keeping the OIDC public keys fresh so that satellites do not have to fetch them on every request.
The reason it exists as a separate piece of infrastructure is practical: OIDC public keys are the same for everyone. There is no point in having each satellite — and by extension each developer — independently fetch and pay for the same HTTP outcall. Having a single place fetch and cache the keys reduces redundant network traffic on the subnet and keeps costs down for everyone.
The core of it is a recurring timer that fetches the JWKS from the provider's URL and stores it. If the fetch fails — which can happen during key rotation, when HTTPS outcall responses are not yet consistent across nodes — it retries with exponential backoff. (source)
pub fn schedule_certificate_update(provider: OpenIdProvider, delay: Option<u64>) {
if assert_scheduler_running(&provider).is_err() {
return;
}
set_timer(Duration::from_secs(delay.unwrap_or(0)), async move {
let result = fetch_and_save_certificate(&provider).await;
let next_delay = if result.is_ok() {
FETCH_CERTIFICATE_INTERVAL
} else {
let backoff = match delay {
Some(delay) if delay < FETCH_CERTIFICATE_INTERVAL => delay.saturating_mul(2),
_ => 60 * 2,
};
min(FETCH_CERTIFICATE_INTERVAL, backoff)
};
schedule_certificate_update(provider, Some(next_delay));
});
}The function is recursive — each run schedules the next one. On success, it waits for the standard interval. On failure, it starts at a 2-minute delay and doubles on each subsequent failure, capping at the standard interval. This matters in practice: during a key rotation, GitHub may temporarily serve inconsistent responses across requests, so retrying too aggressively would just produce more errors.
The actual fetch is straightforward:
async fn fetch_and_save_certificate(provider: &OpenIdProvider) -> Result<(), String> {
let http_result = get_certificate(provider).await?;
let jwks = from_slice::<Jwks>(&http_result.body).map_err(|e| e.to_string())?;
set_openid_certificate(provider, &jwks);
Ok(())
}It fetches, parses the JWKS from JSON, and stores it. The URL comes from the provider implementation — each provider knows its own JWKS endpoint. (source)
impl OpenIdProvider {
pub fn jwks_url(&self) -> &'static str {
match self {
Self::Google => "https://www.googleapis.com/oauth2/v3/certs",
Self::GitHubAuth => "https://api.juno.build/v1/auth/certs",
Self::GitHubActions => "https://token.actions.githubusercontent.com/.well-known/jwks",
}
}
}The HTTP outcall itself uses the Internet Computer's http_request_outcall, which allows programs to make outbound HTTPS requests. The is_replicated flag ensures the call goes through consensus — all nodes in the subnet must agree on the response before it is accepted. (source)
fn get_request(provider: &OpenIdProvider) -> HttpRequestArgs {
let url = provider.jwks_url();
let request_headers = vec![
HttpHeader {
name: "Accept".into(),
value: "application/json".into(),
},
HttpHeader {
name: "User-Agent".into(),
value: "juno_observatory".into(),
},
];
HttpRequestArgs {
url: url.to_string(),
method: HttpMethod::GET,
body: None,
max_response_bytes: Some(FETCH_MAX_RESPONSE_BYTES),
transform: param_transform(),
headers: request_headers,
is_replicated: Some(true),
}
}Once stored, the JWKS is available to any satellite that needs to verify an OIDC token — without having to make an outbound call themselves.
References
- GitHub Actions — OpenID Connect
- junobuild/juno-action
- junobuild/juno-js — includes
@junobuild/auth - junobuild/juno — Satellite, Observatory, and all Rust crates
- Internet Computer — HTTPS Outcalls
Conclusion
That's about it. If you are still here, congratulations! I'm well aware this blog post wasn't easy to follow and most probably dropped while going through all the steps — not speaking of my writing. I hope anyway it was interesting enough to give you some ideas, and if you have any suggestions for improvements, please let me know!