
We are developing a proof of concept to port our web app, DeckDeckGo, to DFINITY's Internet Computer.
After having validated the hosting and password-less authentication integration, we are tackling the last question of our POC: persisting user data and presentations in the blockchain.
Along the way, we tried out two concepts:
- a “conservative” one: a data persistence in a single database-like storage
- a “futuristic 🤯” one: generate a database-like smart contract on the fly for each deck created by a user.
In this article I present these two approaches.
Introduction
The scope of this blog post is limited to simple key-value database concepts. That kind of persistence is the one we rely on in DeckDeckGo.
I do not know if anyone has already implemented heavier concepts with the IC (Internet Computer), such as a fully functional SQL database running on the blockchain.
You can of course challenge these by commenting on the blog post or by reaching out 😃.
The “Nowadays”
Before digging into the Internet Computer, let's first review some common, old fashion concepts.
Nowadays, server-less or not, the data persistence is often solve with one database for all information.
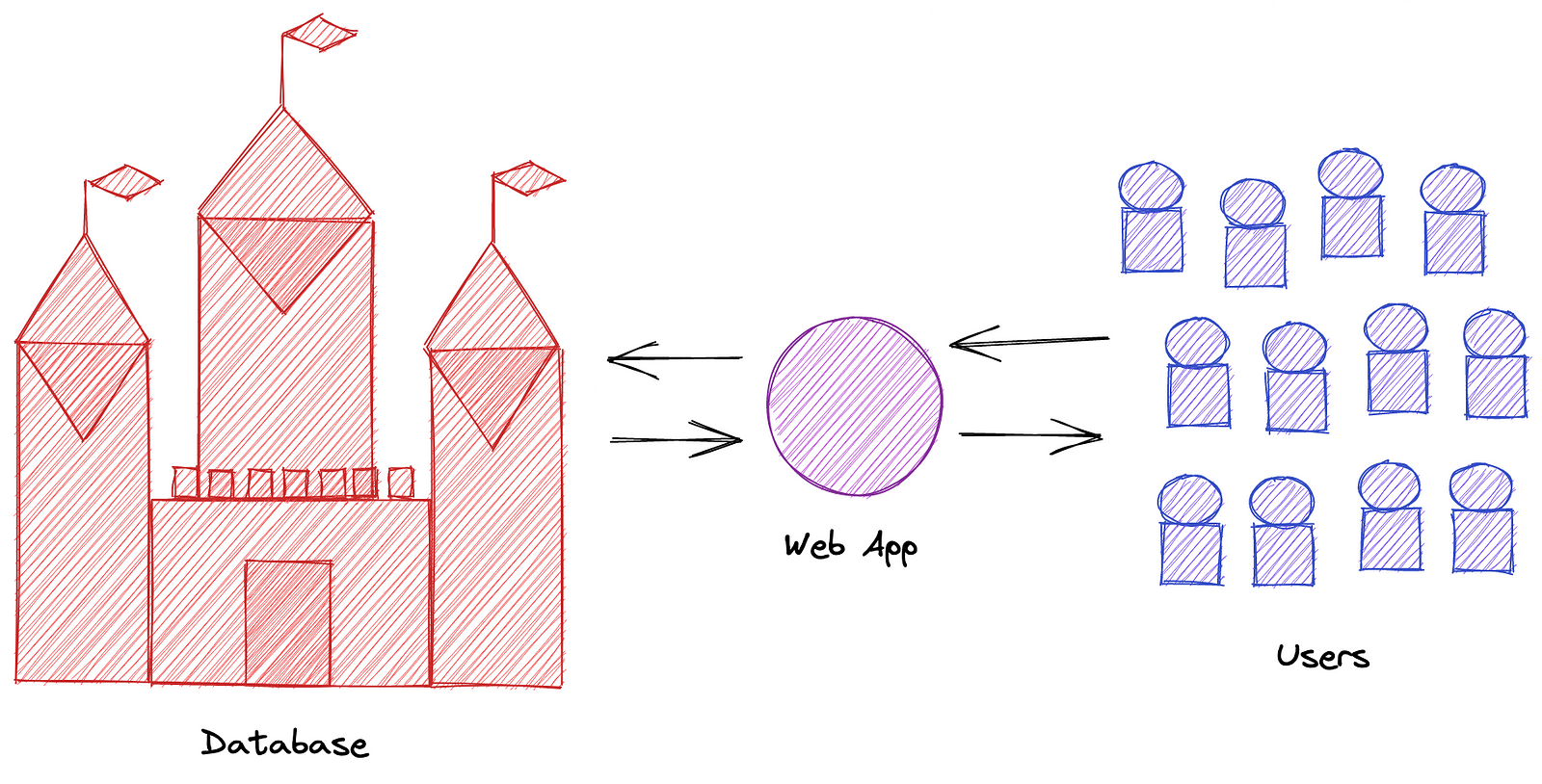
Users use the (web) application. It calls endpoint(s) to persist and read data and, it returns the results to the users.
In a microservice architecture, the application(s) is split as a collection of services but, to some extension, the outcome is based on the same concept.
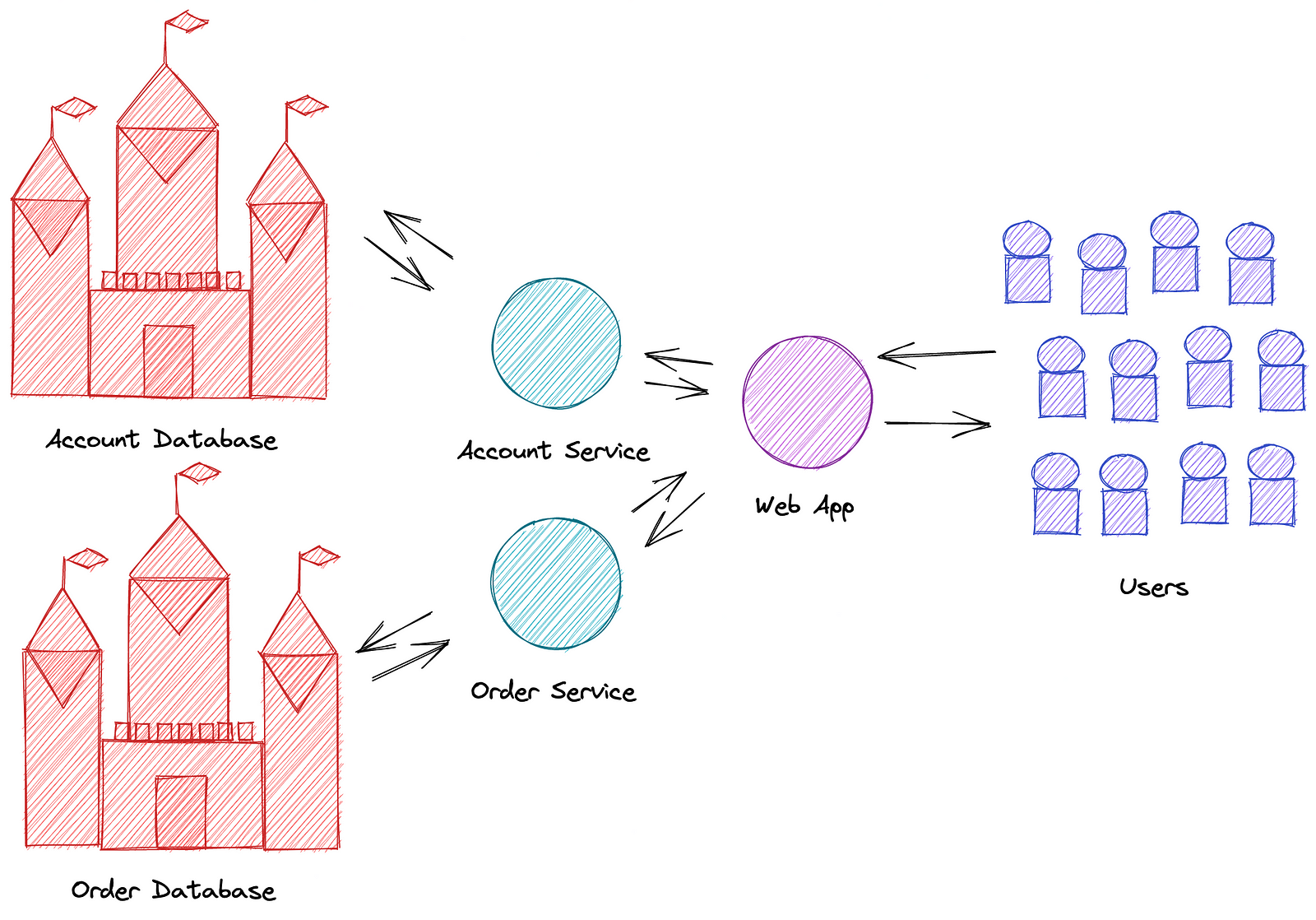
Users use the (web) application. It calls a dedicated service which in turn calls endpoint(s) to persist and read data and, returns the results to the users.
Regardless of these architectures, mono- or micro-services, the data is stored in a monolithic database.
Code Snippet
I do not know the exact architecture of Google Firestore but, from a user and outside point of view, it looks like a mono-database hosted in the cloud.
If we develop, for example, an application that lists the kind of animals our users own, we would most probably define a db collection of pets to collect their entries.
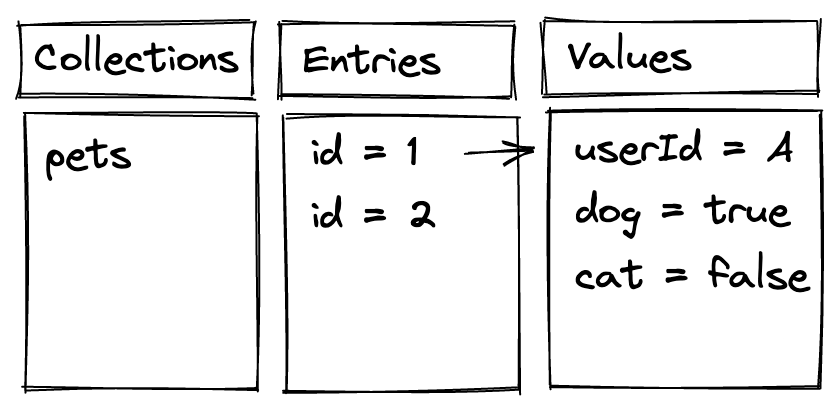
To query and persist the data, we would then implement getter (get ) and setter (add ) functions in our web application that would call the cloud database.
import firebase from "firebase/app";
import "firebase/firestore";
const firestore = firebase.firestore();
const get = async (entryId) => {
const snapshot = await firestore.collection("pets").doc(entryId).get();
if (snapshot.exists) {
console.log(snapshot.data());
}
};
const add = async (userId, dog, cat) => {
const { id: entryId } = await firestore.collection("pets").add({
userId,
dog,
cat
});
console.log(entryId);
};
All users would use the same entry point and their data would also be saved in the same collection (firestore.collection('pets') ).
The “Conservative”
The Internet Computer does not provide a built-in, just-add-water database solution, that is not the goal of the DFINITY foundation (my understanding). They provide a futuristic blockchain network, that can run web applications too. That's "all".
It is up to the makers to build features on top of it. They can implement features and unleash these on the IC through canister smart contracts.
I picture a "canister" as a container that runs a set of functions in the cloud, except that it is actually a decentralized blockchain network 😉. It can basically do anything that can be implemented, from computing to data persistence.
After studying the documentation of the SDK, examples and the “linkedup” demo, our first approach had then for goal to replicate the approach we are familiar with, i.e. the “Nowadays" or "monolithic" database approach.
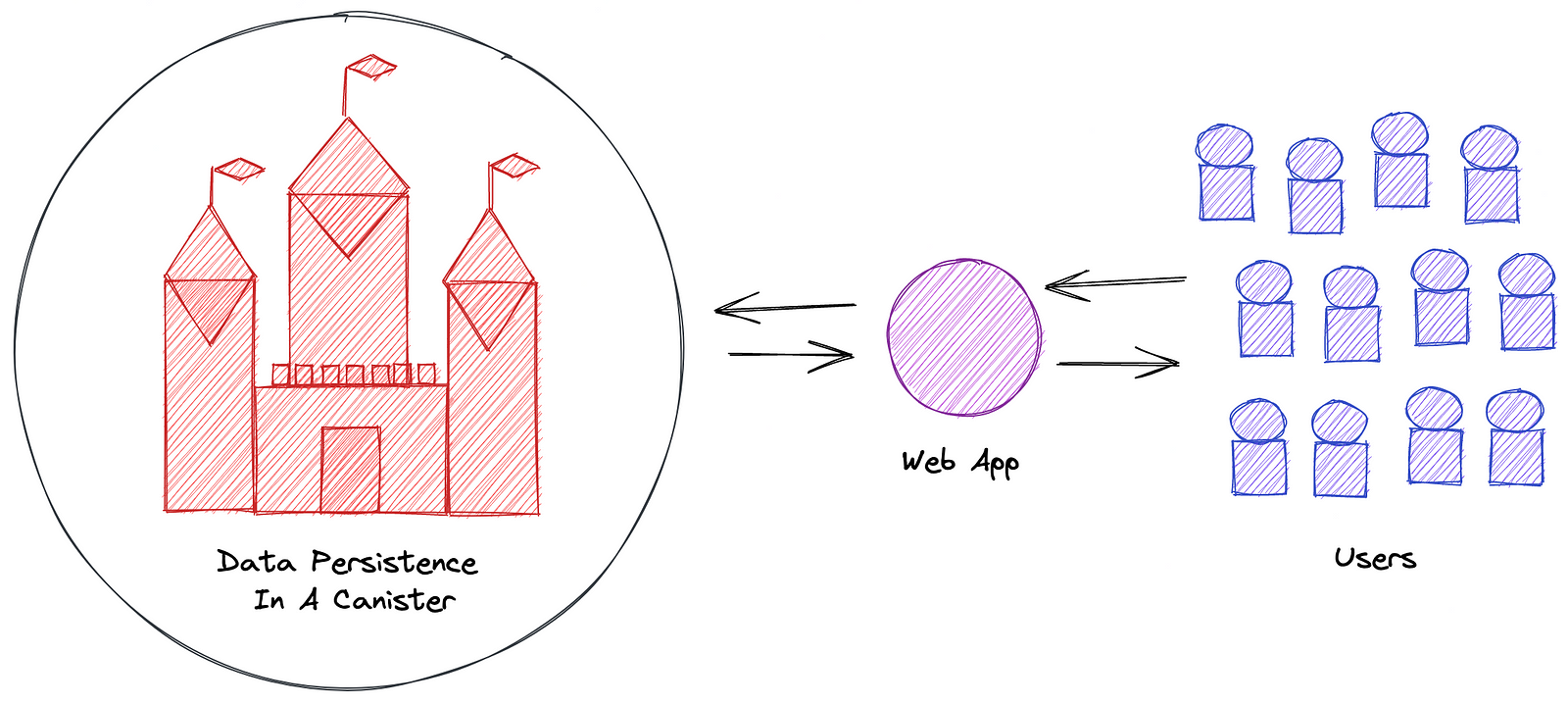
However, given the blockchain nature of the Internet Computer, it may be good to imagine the architecture in a decentralized way with data shared in the form of blocks.
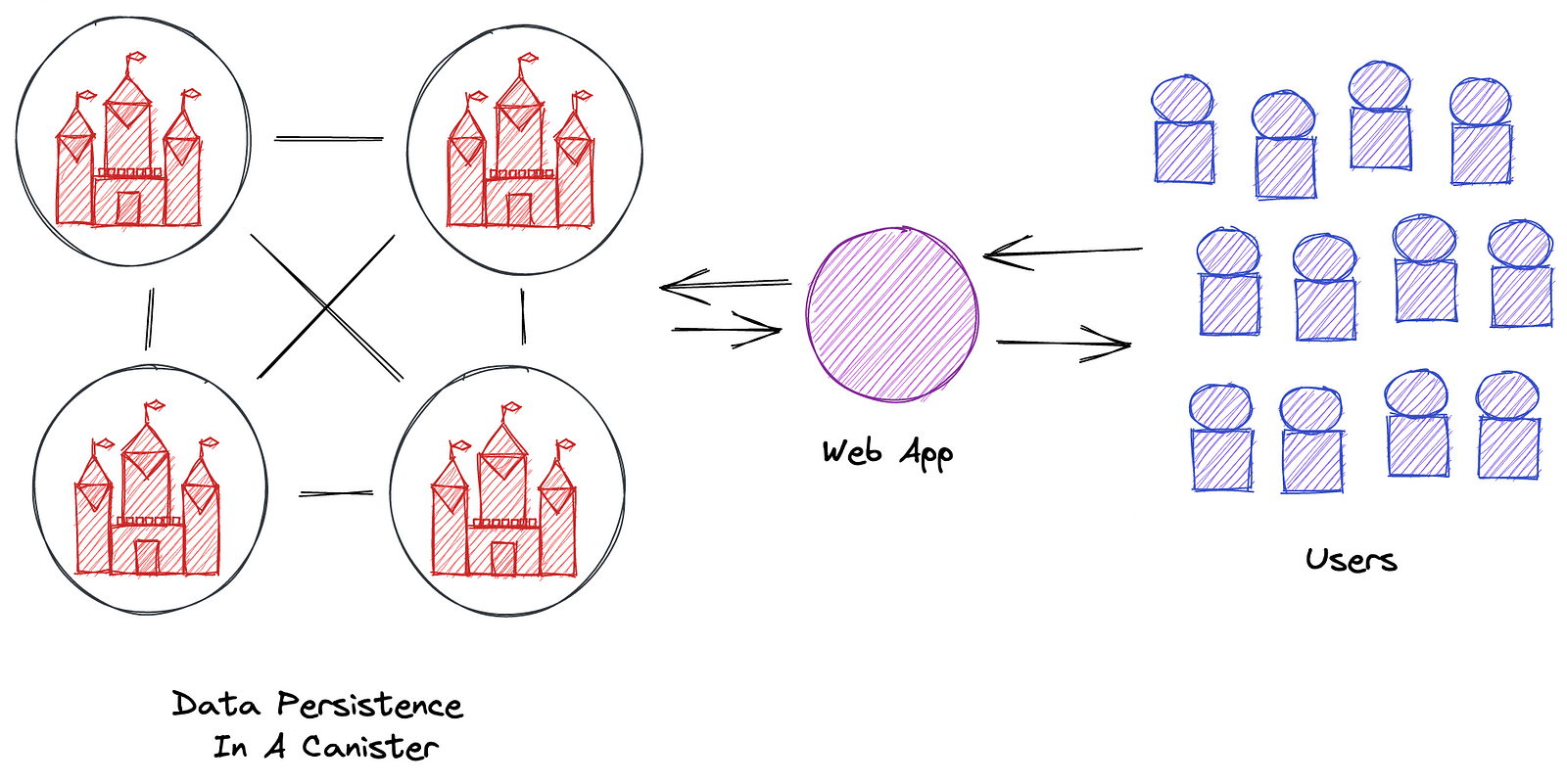
If we omit the blockchain aspect (and the decentralization), it basically works the same as what I am familiar with, doesn't it?
Code Snippet
The way we can picture the persistence of the data within a canister, like we would for our "pets" web application, would be again quite similar to the previous architecture.
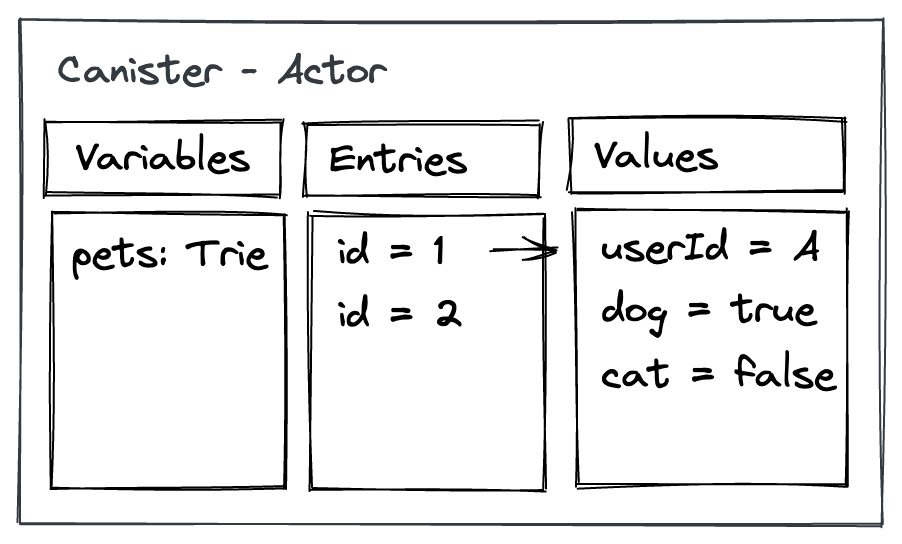
Instead of a key-value database collection -- as there are no built-in databases available -- our actor would simply have an attribute holding the data.
That attribute can for example be a Trie, a functional map (and set) whose representation is “canonical”, and independent of operation history.
To query (get ) and persist (add ) the data, we would be able to implement an actor, a canister, as following:
Canisters and features unleashed in the Internet Computer can commonly either be written in Motoko or Rust. Motoko is published and maintained by the DFINITY foundation and most of the documentation’s examples are provided in that particular programming language. That is mostly why we developed our proof of concept with Motoko.
import Trie "mo:base/Trie";
import Nat32 "mo:base/Nat32";
actor {
type PetId = Nat32;
type Data = {
dog: Bool;
cat: Bool;
userId: Text;
};
private stable var entryId: PetId = 0;
private stable var pets : Trie.Trie<PetId, Data> = Trie.empty();
public func add(userId: Text, dog: Bool, cat: Bool): async () {
let data = {
userId = userId;
dog = dog;
cat = cat;
};
pets := Trie.replace(
pets,
key(entryId),
Nat32.equal,
?data,
).0;
entryId += 1;
};
public query func get(entryId: Nat32) : async ?Data {
let result = Trie.find(pets, key(entryId), Nat32.equal);
return result;
};
private func key(x : PetId) : Trie.Key<PetId> {
return { hash = x; key = x };
};
};
The data would be saved in the canister smart-contract, replicated and decentralized, while using an approach we are familiar with.
Note: Link to related Motoko Playground to try and play with above example.
The “Futuristic 🤯”
Our first "Conservative" approach validated the hypothesis that data persistence for our web application in the Internet Compute could be done. But what about scalability?
In our first approach, we did not use a Trie as in the example; instead we store the data in a HashMap. That way, it would have made the system a bit more scalable, as data would have potentially been still delivered more quickly, even with a large amount of data. However, at some point, we might have hit some limits anyway.
In addition, a canister can only store 4GB of memory pages due to the limitations of WebAssembly implementations (source).
That is why, we challenged our first idea and, and tried to find a more scalable design.
It resulted in an architecture in which a main actor acts as a a manager that -- on the fly, upon object creation -- generates a decentralized secure simple key-value database-like for each single data persistence of each user 🤯.
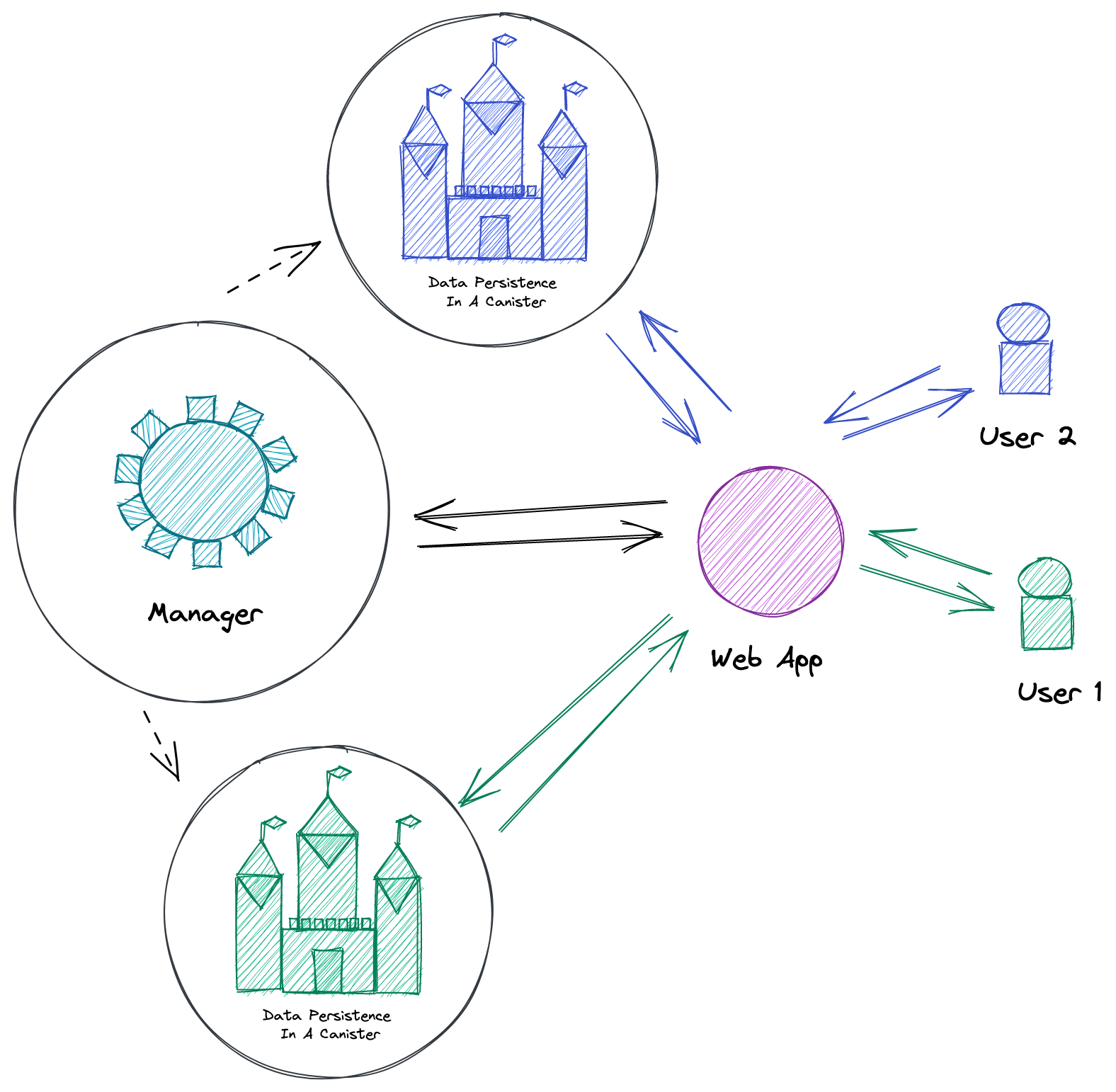
In the above diagram I displayed only two users and, did not reflect the blockchain nature of the network but, hopefully, it pictures well the idea.
A user, through the web app, requests the manager to get him/her a personal decentralized secure simple key-value data persistence canister. Once obtained, he/she uses this dedicated private space to query and persist his/her data.
Code Snippet
We would need two actors to implement such a solution. One that acts as a “manager”, the canister that generates other canisters on the fly, and an implementation for the canisters that take care of the data persistence, those that are generated on the fly.
The “manager” might have to track or not the list of canisters it has generated, unless end users save on their side their references. However, in the following snippet we will assume it does have to keep track of what it generates.
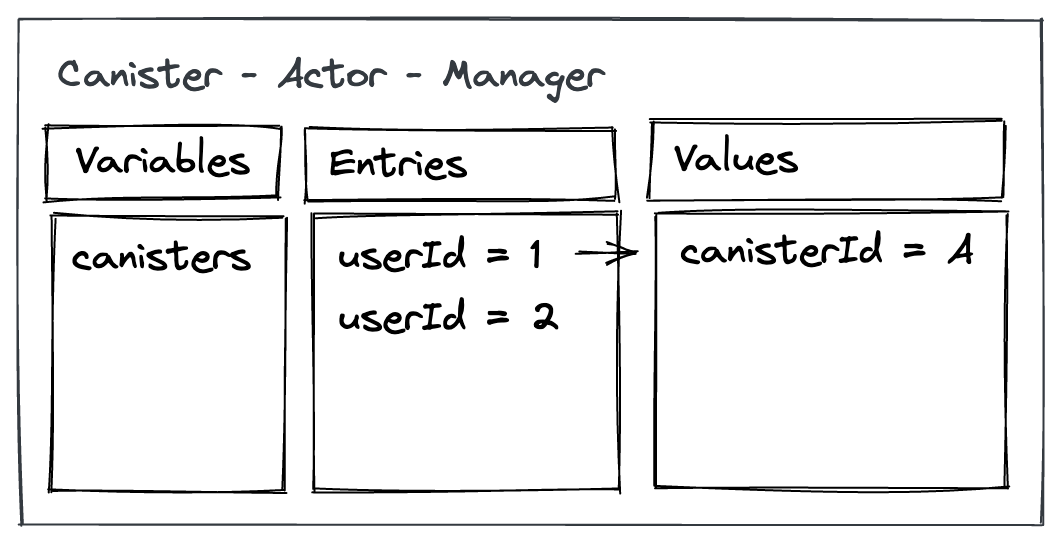
The base implementation of the manager is close to what we already implemented. However, instead of Trie, I used a HashMap to keep track of the IDs of the canisters that has been generated.
import HashMap "mo:base/HashMap";
import Principal "mo:base/Principal";
import Cycles "mo:base/ExperimentalCycles";
import Iter "mo:base/Iter";
import Pet "./Pet";
actor {
type CanisterId = Principal;
type UserId = Principal;
private func isPrincipalEqual(x: Principal, y: Principal): Bool {
x == y
};
private var canisters: HashMap.HashMap<UserId, CanisterId> =
HashMap.HashMap<UserId, CanisterId>(10, isPrincipalEqual,
Principal.hash);
private stable var upgradeCanisters: [(Principal, CanisterId)] =
[];
public shared({caller}) func create(): async (CanisterId) {
Cycles.add(1_000_000_000_000);
let canister = await Pet.Pet();
let id: CanisterId = await canister.id();
canisters.put(caller, id);
return id;
};
public shared query({caller}) func get() : async ?CanisterId {
let id: ?CanisterId = canisters.get(caller);
return id;
};
system func preupgrade() {
upgradeCanisters := Iter.toArray(canisters.entries());
};
system func postupgrade() {
canisters := HashMap.fromIter<UserId, CanisterId>
(upgradeCanisters.vals(), 10,
isPrincipalEqual, Principal.hash);
upgradeCanisters := [];
};
};
The function create takes care of unleashing new users' canisters in the Internet Computer, those that will be used for the data persistence. It first allocates a minimal cycle count for the new actors.
The get function returns, if it exists, the ID of the user’s canister.
Both preupgrade and postupgrade are used to persist the memory between upgrades (see documentation).
Once the manager developed, we would be able to implement an actor dedicated to the personal data persistence of a user.
import Principal "mo:base/Principal";
actor class Pet() = this {
type Data = {
dog: Bool;
cat: Bool;
};
private stable var myPet: ?Data = null;
public func set(dog: Bool, cat: Bool): async () {
myPet := ?{
dog = dog;
cat = cat;
};
};
public query func get() : async ?Data {
return myPet;
};
public query func id() : async Principal {
return Principal.fromActor(this);
};
};
Its implementation looks familiar to what we have seen before, except for a small (but important) modification: there is no entryId anymore and, there is no Trie neither.
Each user has his/her own little kingdom. That's why he/she does not need an identifier to lookup the data in a big pot of data. It doesn't even have to memorize the userId.
It is the user's kingdom, it contains only the personal data of that particular user!
Note: Link to related Motoko Playground to check out above example.
Pros And Cons
The ultimate architecture is really scalable, as every user operates in his/her own realm. It also separates the concern in clear ownerships and fits well a secure approach.
However, it is worth noting that it is linked with more administration, whether during upgrade of their codes or handling their costs.
Nevertheless, we are big fans of this architecture and think that the advantages are totally worth it. Therefore, it is the concept we would use if our proof of concept would turn into a real live productive use case.
After all, great power comes with great responsibility!
Summary
It is quite a tricky subject. I hope I was able to communicate the main idea behind these architectures and, most importantly, behind the one I called the “Futuristic one 🤯”.
To infinity and beyond!
David
Grant Program
We are incredibly lucky to have been selected for DFINITY Developer Grant Program to support the developer ecosystem, award teams to build dapps, tooling, and infrastructure on the Internet Computer.
I cannot stress enough the fact that if you have a great project you should definitely apply. It has been so far nothing less than an amazing experience and, just give the feeling to take part to something that is ahead of its time.
All figures of this article have been developed with Excalidraw, what a slick drawing tool.